



 Support Center
Support Center
Smarter at the Source: On-Sensor AI Processing
Table of Contents
Sony IMX501: Vision and Intelligence in One Package
On-Sensor AI vs. Traditional Processing
Traditional machine vision sensors typically capture raw image data and rely on external systems, such as PCs or cloud servers, for processing and analysis. While this approach can support large, complex AI models and allows for more advanced pre- and post-processing, it can be far above what’s required for many users. Moreover, it introduces additional latency, increases power and bandwidth demands, and results in much higher system complexity and cost.
By contrast, integrating AI processing directly into the sensor itself enhances data processing efficiency and decision-making speed, while also freeing up host PC resources for other tasks. Machine learning algorithms running on-device allow for more immediate inference, eliminating the need to transfer large volumes of image data to centralized systems. Despite its leaner processing resources, this architecture can provide efficient and effective performance for many practical use cases and can meet the needs of most users. The result: faster responses, reduced bandwidth usage, and more compact, cost-effective systems.

Stacked AI Sensor Architecture
Sony’s IMX501 exemplifies this new class of intelligent sensors. It is a 12.3 MP (4056 x 3040 px) backside-illuminated CMOS rolling shutter sensor that features on-sensor AI engine enabled by an integrated Convolutional Neural Network (CNN) processor. The main AI processing components are composed of an ISP for pre-processing CNN input images, a Digital Signal Processor (DSP) subsystem for CNN operations, and 8 MB of L2 SRAM for storing CNN weights and runtime data. The AI components are built on a separate die and stacked below the top die (the pixel array sensor). Thanks to this stacking architecture, AI inference on the IMX501 is performed entirely on the sensor package with high-speed image data transfer between the two dies, supporting an internal processing rate of about 30 frames per second at full resolution. However, actual image readout performance depends on the bandwidth between the sensor and the camera’s FPGA, while CNN inference time varies with the complexity and size of the AI model. Overall throughput is further limited by the 1GigE camera interface, which caps the maximum data transfer rate for both image output and processing.
The IMX501’s stacked sensor and AI dies enable fast on-package data transfer at ~30 fps at 12.3MP, though real-world performance depends on sensor-FPGA bandwidth, AI model complexity, and 1GigE interface limits.
| Triton Smart Framerates (Max FPS) |
7.9 FPS @ 12.3 MP (Full image with Object Detection) 29 FPS (4×4 image with Object Detection) 8.0 FPS @ 12.3 MP (Full image with Classification / Anomaly Detection) 30 FPS (4×4 image with Classification / Anomaly Detection) |
Parallel DSP Cores for Efficient AI Inference
The main engine for AI processing is the DSP subsystem core. This core is comprised of a High-Computation-Intensity (CI) DSP core, Standard-CI DSP core, and Tensor DMAs (TDMAs). The High-CI and Standard-CI DSPs work in parallel, executing neural network operations and moving the data directly into TDMA and then into L2 memory. Image and inference data are then transferred via the MIPI interface to the camera’s FPGA.
The CNN processor contains both a High- and Standard-CI DSP core. Both DSP cores contain multiple processing elements (PE), memory-access elements (ME), and registers (RE). This architecture provides sufficient processing power to effectively run classification, detection, and anomaly models.















The Standard-CI DSP core is optimized for general-purpose, irregular, and sequential tasks, allowing the High-CI DSP core to remain dedicated to compute-intensive operations. Because the Standard-CI core handles workloads with higher memory access demands, it integrates a greater number of Memory Engines (MEs).

The High-CI DSP core is optimized for high-throughput tasks such as convolutions and matrix operations, efficiently reusing data to minimize memory accesses. To support this, it integrates a larger number of Processing Elements (PEs) and increased register (RE) storage capacity.
This sensor architecture enables the IMX501 to perform power-efficient AI inference, consuming only about 280 mW during full-resolution processing. All inference runs entirely offline, with no need for internet or cloud connectivity, making it well-suited for automation environments that require fully self-contained, air-gapped networks to reduce external dependencies and potential points of failure.
Brain Builder for AITRIOS: Building Accurate Models with No Deep Learning Expertise
To fully leverage the IMX501’s on-sensor AI capabilities, an equally optimized software pipeline is essential given the sensor’s strict memory limitations. The Triton Smart camera utilizes a special version of Neurala’s Brain Builder: Brain Builder for AITRIOS. This AI model training platform not only produces AI models but also eliminates the need for manual model pruning, compression, or architecture tuning. Users can build accurate classification and object detection models with as few as 50 images per class. The software automatically handles model optimization, selects suitable neural network architectures, and ensures seamless integration with the Triton Smart, making AI model development efficient and accessible, even for users without deep learning expertise.
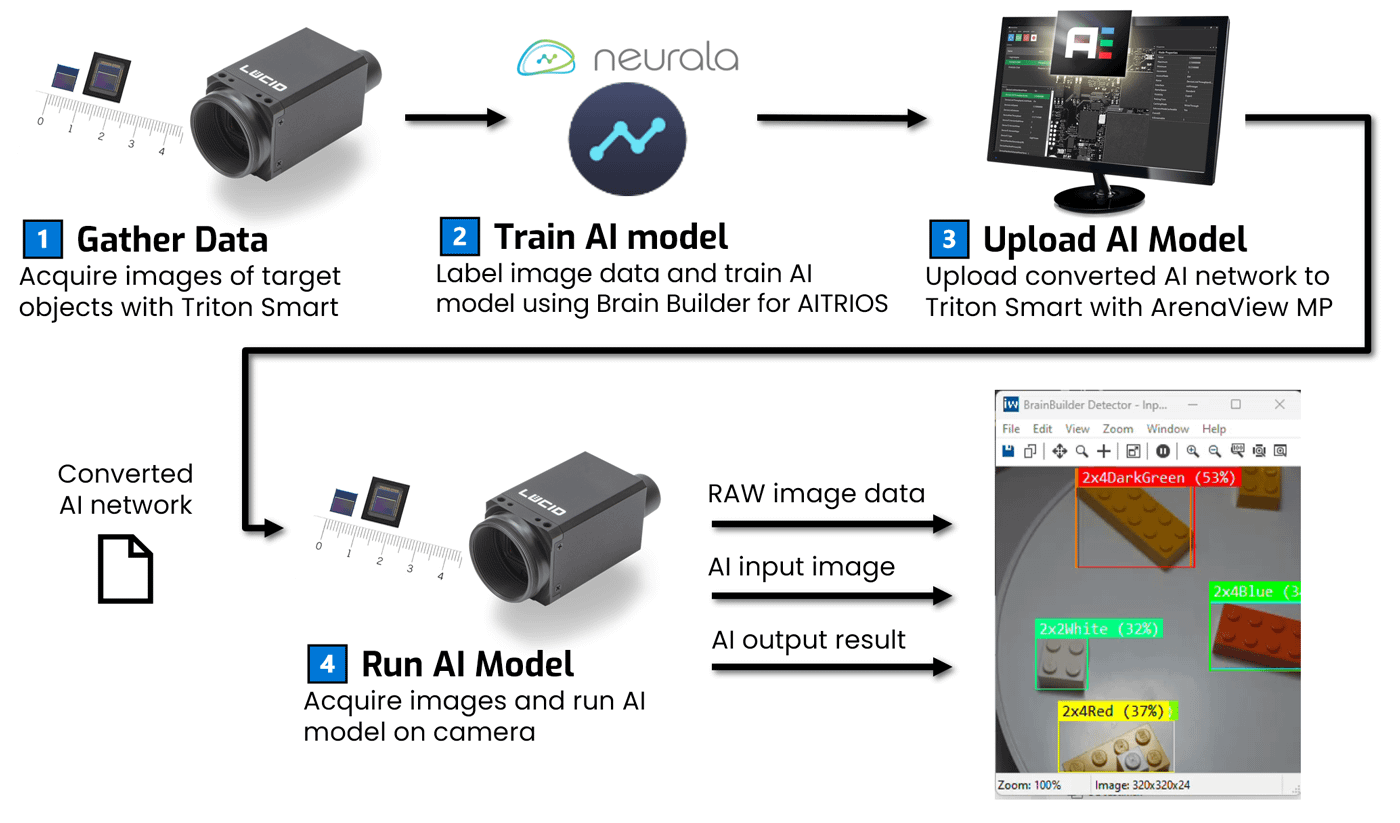
Users upload their image dataset, define classes and label images. Users can review how many classes have been labeled in the dataset before starting the model training.
(The video above utilizes a sample dataset included in the Brain Builder software package. For clarity and viewing convenience, some stages in this video have been sped up and edited. All key information is still presented.)
The basic steps to creating a model in Brain Builder for AITRIOS are: 1) Name your project. 2) Choose your Model Type. 3) Upload images. 4) Create classes (labels). 5) Annotate your images. 6) Choose your Training Comprehensiveness and Train
Triton Smart: Rugged AI at the Edge
29 x 29 mm
67 grams
M12 / M8 Connectors
-20°C to 55°C Ambient
LUCID’s Triton Smart camera integrates the IMX501 into a compact, lightweight housing (67 g, 29 x 29 mm) designed for industrial environments. Its durable two-piece aluminum case is sealed and secured with four M2 screws, while robust M12 and M8 connectors ensure reliable Ethernet and GPIO connections. For dusty or wet conditions, an optional IP67-rated lens tube offers additional protection without the need for a separate enclosure.
Operating within a wide ambient temperature range (-20°C to 55°C), and engineered to withstand shock and vibration, the Triton Smart is built for long-term use on the factory floor, in logistics centers, or in outdoor installations.

Dual ISPs
The Triton Smart features a dual-ISP design that enables simultaneous AI and image processing. The IMX501 sensor’s built-in ISP pre-processes captured images into an input tensor for the AI engine. Different AI models have specific input tensor specifications: Classification is 256 x 256 pixels, Object Detection is 320 x 320 pixels, and Anomaly Detection is 512 x 512 pixels. After inference, the output tensor is generated, with both tensors containing the results of the AI analysis.
Meanwhile, the raw image data is routed to a secondary ISP in the camera’s FPGA, which performs conventional image processing like a standard machine vision camera. The AI results are embedded as chunk data and combined with the final image, providing both visual output and metadata to the host PC in a single data stream. The camera provides three output options: a regular image, the input tensor (downsampled image sent to the AI engine), and the output tensor (inference results). For applications requiring higher frame rates or enhanced privacy, users can optionally reduce the regular image to just 4 × 4 pixels while receiving the input / output tensor. Operating at full resolution (4056 × 3040 px) alongside AI inference results yield an output of 8.3 FPS. By reducing the regular image to 4 × 4 pixels, the camera can achieve up to 30 FPS with AI inference.
This dual-path architecture ensures that high-quality imaging and real-time AI inference can occur in parallel without sacrificing standard camera image processing features such as gain, gamma, black level, white balance, LUT, CCM, pixel correction, hue, saturation, color space conversion, and ROI.

Real-World Applications
With AI inference embedded directly in the camera, the Triton Smart is ideal for applications where low latency, offline capability, and power efficiency are essential.
Key use cases include:
- Smart Manufacturing: In-line defect detection, component verification, and predictive maintenance.
- Retail and Smart Kiosks: Inventory tracking, shelf analytics, and unattended checkout systems.
- Logistics and Warehousing: Real-time package sorting, label reading, and bin verification.
- Access Control and Public Safety: Intrusion detection, people counting, and secure zone monitoring.
Bringing AI Closer to the Data Source
On-sensor AI processing is redefining what’s possible at the edge. While the Triton Smart isn’t intended to replace high-performance AI servers, it provides an effective balance of efficiency and capability for many industrial and embedded applications. By enabling real-time decision-making within the sensor, solutions like LUCID’s Triton Smart with Sony’s IMX501 reduce system complexity, enhance responsiveness, and operate independently of cloud or host infrastructure. Combined with intuitive tools like Brain Builder for AITRIOS, this approach lowers the barrier to AI adoption in machine vision and brings intelligent automation within reach for a broader range of users.
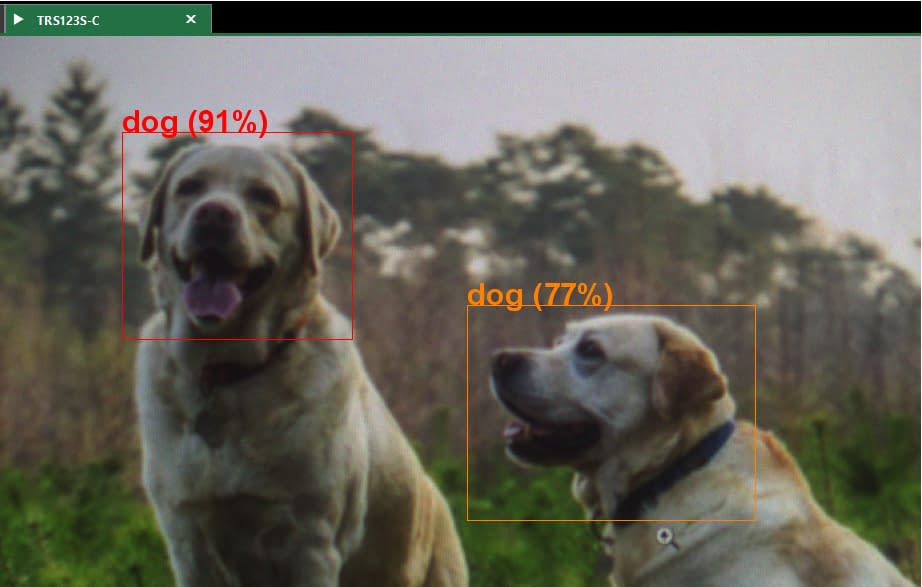
Models that have been created by Brain Builder for AITRIOS can be loaded onto the Triton Smart using AreanView MP. Real-time AI inference results can be visualized on ArenaView MP.